متلب فا | دنیای تحقیق و پروژه
متلب فا | دنیای تحقیق و پروژه

یادگیری عمیق یکی از شاخههای یادگیری ماشین است که بر پایه شبکههای عصبی مصنوعی با لایههای متعدد بنا شده است تا از دادهها یاد بگیرد و پیشبینیهایی انجام دهد. شبکه عصبی مصنوعی بر اساس ساختار و کارکرد نورونهای بیولوژیکی که در مغز یافت میشوند، طراحی شده است.
این مجموعه سوالات و پاسخها، از سطح مقدماتی تا پیشرفته درباره یادگیری عمیق را پوشش و به شما بینش لازم برای حضور در یک مصاحبه فنی را میدهد. این سوالات یادگیری عمیق توسط حرفهایهای باتجربه در زمینه دادهکاوی پیشنهاد شدهاند. بنابراین، انتظار می رود بتواند به شما کمک کند.
فهرست مطالب
۱. یادگیری عمیق چیست؟
یادگیری عمیق یکی از شاخههای یادگیری ماشین است که بر مبنای معماری شبکههای عصبی مصنوعی قرار دارد و این توانایی را دارد که الگوها و روابط پیچیدهای را در دادهها یاد بگیرد. یک شبکه عصبی مصنوعی یا ANN از لایههایی از گرههای متصل به هم به نام نورونها استفاده میکند که برای پردازش و یادگیری از دادههای ورودی با هم کار میکنند.
در یک شبکه عصبی عمیق کاملاً متصل، یک لایه ورودی و یک یا چند لایه پنهان وجود دارد که به ترتیب به یکدیگر متصل میشوند. هر نورون، ورودیها را از نورونهای لایه قبلی یا لایه ورودی دریافت میکند. خروجی هر نورون به عنوان ورودی برای نورونهای لایه بعدی در شبکه تبدیل میشود و این فرآیند ادامه مییابد تا لایه نهایی، خروجی شبکه را تولید کند. لایههای شبکه عصبی دادههای ورودی را از طریق یک سری تبدیلات غیرخطی تغییر میدهند، که به شبکه اجازه میدهد تا نمایشهای پیچیدهای از دادههای ورودی را یاد بگیرد.
امروزه یادگیری عمیق به دلیل موفقیت آن در کاربردهای متنوعی مانند بینایی کامپیوتری، پردازش زبان طبیعی و یادگیری تقویتی، به یکی از محبوبترین و برجستهترین زمینههای یادگیری ماشین تبدیل شده است.
۲. شبکه عصبی مصنوعی چیست؟
شبکه عصبی مصنوعی از شبکهها و عملکردهای نورونهای بیولوژیکی انسان الهام گرفته شده است و به عنوان شبکههای عصبی یا شبکههای نورونی نیز شناخته میشود. ANN از لایههایی از گرههای متصل به هم به نام نورونهای مصنوعی استفاده میکند که با هم کار میکنند تا دادههای ورودی را پردازش و یاد بگیرند. لایه شروع شبکه عصبی مصنوعی به عنوان لایه ورودی شناخته میشود، که ورودی را از منابع ورودی خارجی دریافت میکند و آن را به لایه بعدی که به عنوان لایه پنهان شناخته میشود منتقل میکند، جایی که هر نورون ورودیها را از نورونهای لایه قبلی دریافت میکند و مجموع وزندار را محاسبه میکند و به نورونهای لایه بعدی منتقل میکند. این اتصالات وزندار به این معنی است که تأثیرات ورودیها از لایه قبلی با اختصاص وزنهای مختلف به هر ورودی بیشتر یا کمتر بهینه میشوند و در طی فرآیند آموزش با بهینهسازی این وزنها برای عملکرد بهتر مدل تنظیم میشوند. خروجی یک نورون به عنوان ورودی به نورونهای دیگر در لایه بعدی شبکه تبدیل میشود و این فرآیند ادامه مییابد تا لایه نهایی خروجی شبکه را تولید کند.
۳. یادگیری عمیق چه تفاوتی با یادگیری ماشین دارد؟
یادگیری ماشین و یادگیری عمیق هر دو زیرمجموعههایی از هوش مصنوعی هستند اما بین آنها شباهتها و تفاوتهای زیادی وجود دارد.
| یادگیری ماشین | یادگیری عمیق |
|---|---|
|
الگوریتمهای آماری را برای کشف الگوها و روابط پنهان در مجموعه دادهها به کار میبرد. |
از معماری شبکههای عصبی مصنوعی برای یادگیری الگوها و روابط پنهان در مجموعه دادهها استفاده میکند. |
|
میتواند با مقدار کمتری از دادهها کار کند. |
نسبت به یادگیری ماشین به حجم بیشتری از دادهها نیاز دارد. |
|
برای وظایف با تعداد برچسبهای کم مناسبتر است. |
برای وظایف پیچیده مانند پردازش تصویر، پردازش زبان طبیعی و غیره مناسبتر است. |
|
زمان کمتری برای آموزش مدل نیاز دارد. |
زمان بیشتری برای آموزش مدل نیاز دارد. |
|
مدل با استفاده از ویژگیهای مرتبط که به صورت دستی از تصاویر استخراج میشوند برای تشخیص شیء در تصویر ساخته میشود. |
ویژگیهای مرتبط به صورت خودکار از تصاویر استخراج میشوند و فرآیند یادگیری از ابتدا تا انتها است. |
|
کم پیچیدگی دارد و تفسیر نتایج آسانتر است. |
پیچیدهتر است و مانند یک جعبه سیاه عمل میکند، تفسیر نتایج آسان نیست |
|
میتواند روی CPU کار کند یا نیاز به قدرت محاسباتی کمتری دارد نسبت به یادگیری عمیق. |
نیاز به کامپیوتر با عملکرد بالا و GPU دارد. |
۴. کاربردهای یادگیری عمیق چیست؟
یادگیری عمیق کاربردهای فراوانی دارد و به طور کلی به سه دسته بینایی کامپیوتری، پردازش زبان طبیعی (NLP) و یادگیری تقویتی تقسیم میشود.
- بینایی کامپیوتری: یادگیری عمیق از شبکههای عصبی با لایههای متعدد استفاده میکند که این امکان را به آن میدهد تا برای یادگیری خودکار و شناسایی الگوهای پیچیده در تصاویر به کار رود. ماشینها میتوانند وظایفی مانند طبقهبندی تصویر، تقسیمبندی تصویر، تشخیص شیء و تولید تصویر را با دقت انجام دهند. این امر دقت و کارایی الگوریتمهای بینایی کامپیوتری را به شدت افزایش داده است، که استفادههای متنوعی را در صنایعی مانند بهداشت و درمان، حمل و نقل و سرگرمی ممکن ساخته است.
- پردازش زبان طبیعی (NLP): پردازش زبان طبیعی (NLP) به شدت از یادگیری عمیق بهرهمند شده است، که مدلسازی زبان، تحلیل احساسات و ترجمه ماشینی را بهبود بخشیده است. مدلهای یادگیری عمیق توانایی کشف خودکار ویژگیهای زبانی پیچیده از دادههای متنی را دارند، که پردازش دقیقتر و مؤثرتر ورودیها به زبان طبیعی را ممکن میسازد.
- یادگیری تقویتی: یادگیری عمیق در یادگیری تقویتی برای ارزیابی ارزش اقدامات مختلف در حالتهای مختلف استفاده میشود، که به عامل اجازه میدهد تصمیمات بهتری بگیرد که میتواند پاداشهای پیشبینی شده را به حداکثر برساند. با یادگیری از این اشتباهات، یک عامل در نهایت عملکرد خود را افزایش میدهد. کاربردهای یادگیری عمیق که از یادگیری تقویتی استفاده میکنند شامل بازیها، رباتیک و سیستمهای کنترلی است.
۵. چالشهای یادگیری عمیق چیست؟
یادگیری عمیق پیشرفتهای قابل توجهی در زمینههای مختلف داشته است، اما هنوز چالشهایی وجود دارد که باید مورد توجه قرار گیرند. در اینجا برخی از اصلیترین چالشها در یادگیری عمیق آورده شده است:
- دسترسی به دادهها: برای یادگیری نیاز به مقادیر زیادی داده دارد. برای استفاده از یادگیری عمیق، جمعآوری دادههای زیاد برای آموزش یک دغدغه بزرگ است.
- منابع محاسباتی: برای آموزش مدل یادگیری عمیق، از نظر محاسباتی گران است زیرا نیاز به سختافزارهای تخصصی مانند GPUها و TPUها دارد.
- زمانبر بودن: هنگام کار با دادههای ترتیبی بسته به منابع محاسباتی ممکن است زمان زیادی حتی به روزها یا ماهها ببرد.
- قابلیت تفسیر: مدلهای یادگیری عمیق پیچیده هستند، مانند یک جعبه سیاه کار میکنند. تفسیر نتیجه بسیار دشوار است.
- بیشبرازش: وقتی مدل بارها و بارها آموزش داده میشود، بیش از حد برای دادههای آموزشی تخصصی میشود، که منجر به بیشبرازش و عملکرد ضعیف در دادههای جدید میشود.
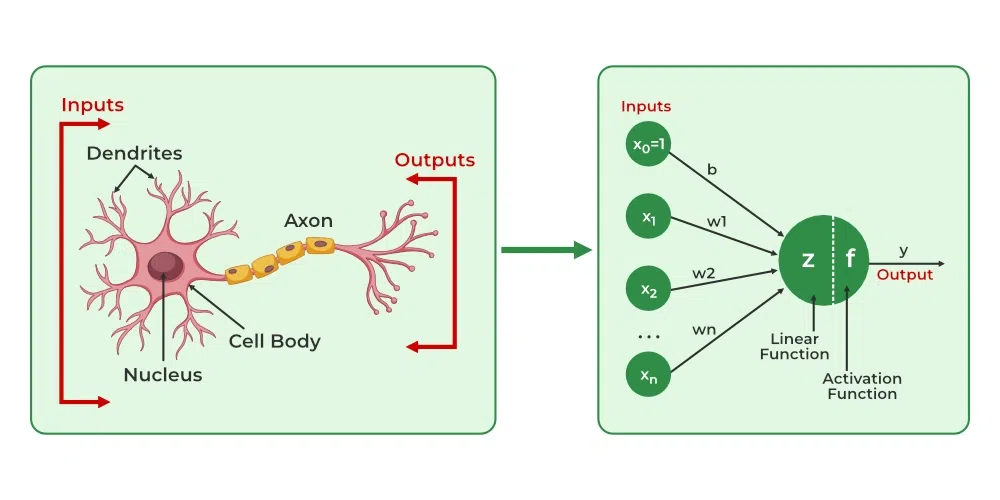
۶. نورونهای بیولوژیکی چگونه به شبکه عصبی مصنوعی شباهت دارند؟
مفهوم شبکههای عصبی مصنوعی از نورونهای بیولوژیکی که در مغز حیوانات یافت میشوند، گرفته شده است، بنابراین آنها شباهتهای زیادی از نظر ساختاری و کارکردی دارند.
- ساختار: ساختار شبکههای عصبی مصنوعی از نورونهای بیولوژیکی الهام گرفته شده است. یک نورون بیولوژیکی دارای دندریتها برای دریافت سیگنالها، یک بدنه سلولی یا سوما برای پردازش آنها و یک آکسون برای انتقال سیگنال به نورونهای دیگر است. در شبکههای عصبی مصنوعی سیگنالهای ورودی توسط گرههای ورودی دریافت میشوند، گرههای لایه پنهان این سیگنالهای ورودی را محاسبه میکنند و گرههای لایه خروجی خروجی نهایی را با پردازش خروجیهای لایه پنهان با استفاده از توابع فعالسازی محاسبه میکنند.
- سیناپسها: در نورونهای بیولوژیکی، سیناپسها اتصالات بین نورونها هستند که انتقال سیگنالها از دندریتها به بدنه سلولی و از بدنه سلولی به آکسون را ممکن میسازند. در نورونهای مصنوعی، سیناپسها به عنوان وزنهایی شناخته میشوند که گرههای یک لایه را به گرههای لایه بعدی متصل میکنند. مقدار وزن قدرت بین اتصالات را تعیین میکند.
- یادگیری: در نورونهای بیولوژیکی، یادگیری در بدنه سلولی یا سوما که دارای هستهای است که به پردازش سیگنالها کمک میکند، رخ میدهد. اگر سیگنالها به اندازه کافی قوی باشند تا به آستانه برسند، یک پتانسیل عمل ایجاد میشود که از طریق آکسونها حرکت میکند. این امر توسط پلاستیسیتی سیناپتیک، که توانایی سیناپسها برای تقویت یا ضعیف شدن با گذشت زمان، در پاسخ به افزایش یا کاهش فعالیت آنها است، محقق میشود. در شبکههای عصبی مصنوعی، فرآیند یادگیری به عنوان بازگشتپذیری شناخته میشود، که وزن بین گرهها را بر اساس تفاوت یا هزینه بین خروجیهای پیشبینی شده و واقعی تنظیم میکند.
- فعالسازی: در نورونهای بیولوژیکی، فعالسازی نرخ آتش نورون است که زمانی رخ میدهد که سیگنالها به اندازه کافی قوی باشند تا به آستانه برسند. و در شبکههای عصبی مصنوعی، فعالسازیها توسط توابع ریاضی به نام توابع فعالسازی انجام میشود که ورودی را به خروجی نگاشت میکنند.
۷. چگونه یادگیری عمیق در یادگیری ماشین نظارتی، غیرنظارتی و همچنین تقویتی استفاده میشود؟
یادگیری عمیق میتواند برای یادگیری ماشین نظارتی، غیرنظارتی و همچنین تقویتی استفاده شود. از روشهای متنوعی برای پردازش اینها استفاده میکند.
- یادگیری ماشین نظارتی: یادگیری ماشین نظارتی تکنیک یادگیری ماشین است که در آن شبکه عصبی یاد میگیرد بر اساس مجموعه دادههای برچسبدار پیشبینی یا طبقهبندی دادهها را انجام دهد. در اینجا ما هم ویژگیهای ورودی و هم متغیرهای هدف را وارد میکنیم. شبکه عصبی یاد میگیرد بر اساس هزینه یا خطایی که از تفاوت بین پیشبینیها و هدف واقعی حاصل میشود، پیشبینیها را انجام دهد، این فرآیند به عنوان بازگشتپذیری شناخته میشود. الگوریتمهای یادگیری عمیق نظیر شبکههای عصبی کانولوشنی و شبکههای عصبی بازگشتی در بسیاری از کارهای نظارتی مانند طبقهبندی تصاویر، شناسایی، تحلیل احساسات، ترجمه زبان و غیره به کار گرفته میشوند.
- یادگیری ماشین غیرنظارتی: در یادگیری ماشین غیرنظارتی، شبکه عصبی یاد میگیرد تا الگوها را کشف کند یا دادهها را بر اساس مجموعههای دادهای بدون برچسب خوشهبندی کند. در این روش، متغیرهای هدف وجود ندارند و ماشین باید به طور خودکار الگوهای پنهان یا روابط درون دادهها را شناسایی کند. الگوریتمهای یادگیری عمیق مانند خودرمزنگارها و مدلهای تولیدی برای کارهای غیرنظارتی مانند خوشهبندی، کاهش بعدیت و تشخیص ناهنجاریها به کار میروند.
- یادگیری ماشین تقویتی: در یادگیری ماشین تقویتی، یک عامل یاد میگیرد تا در یک محیط تصمیمگیری کند به گونهای که سیگنال پاداش را به حداکثر برساند. عامل با انجام دادن اقدامات و مشاهده پاداشهای ناشی از آن با محیط تعامل میکند. یادگیری عمیق میتواند برای یادگیری سیاستها یا مجموعهای از اقدامات که پاداش تجمعی را بر زمان حداکثر میکند، به کار رود. الگوریتمهای یادگیری تقویتی عمیق مانند شبکههای Q عمیق و گرادیان سیاست مشخص عمیق (DDPG) برای تقویت کارهایی مانند رباتیک و بازیهای کامپیوتری و غیره به کار میروند.
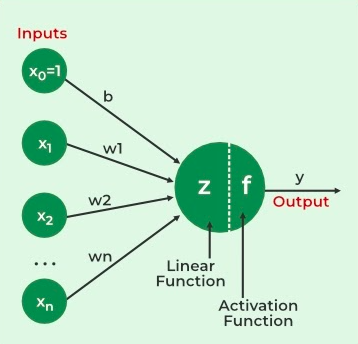
۸. پرسپترون چیست؟
پرسپترون یکی از سادهترین ساختارهای شبکه عصبی مصنوعی است که توسط فرانک روزنبلات در دهه ۱۹۵۰ معرفی شد. این شبکه سادهترین نوع شبکههای عصبی پیشخور را تشکیل میدهد و شامل یک لایه واحد از گرههای ورودی است که به طور کامل به لایهای از گرههای خروجی متصل میشوند. پرسپترون قادر است الگوهایی که به صورت خطی از هم قابل تفکیک هستند را یاد بگیرد. این شبکه از نوعی نورون مصنوعی متفاوت به نام واحدهای منطقی آستانهای (TLU) استفاده میکند که اولین بار توسط مککالاک و والتر پیتس در دهه ۱۹۴۰ معرفی شدند. پرسپترون مجموع وزندار ورودیهای خود را محاسبه میکند و سپس تابع پلهای را برای مقایسه این مجموع وزندار با آستانه به کار میبرد. رایجترین تابع پلهای که در پرسپترون استفاده میشود، تابع پلهای هویساید است.
پرسپترون دارای یک لایه واحد از واحدهای منطقی آستانهای است که هر TLU به تمام ورودیها متصل است. وقتی تمام نورونها در یک لایه به هر نورون لایه قبلی متصل هستند، به عنوان یک لایه کاملاً متصل یا لایه متراکم شناخته میشود. در طول آموزش، وزنهای پرسپترون برای کمینه کردن تفاوت بین مقدار واقعی و پیشبینی شده با استفاده از قانون یادگیری پرسپترون تنظیم میشوند.
w_i = w_i + (learning_rate * (true_output - predicted_output) * x_i)
در اینجا، x_i و w_i به ترتیب iامین ویژگی ورودی و وزن iامین ویژگی ورودی هستند.
۹. پرسپترون چند لایه چیست و چه تفاوتی با پرسپترون تک لایه دارد؟
پرسپترون چند لایه (MLP) نسخه پیشرفتهتری از پرسپترون تک لایه است که از چندین لایه پنهان برای پردازش دادهها از ورودی تا پیشبینی نهایی استفاده میکند. این شبکه از چندین لایه نورونهای متصل به هم تشکیل شده است، با چندین گره در هر لایه. معماری MLP به عنوان شبکه عصبی پیشخور شناخته میشود زیرا دادهها در یک جهت جریان دارند، از لایه ورودی از طریق یک یا چند لایه پنهان به لایه خروجی.
تفاوتهای بین پرسپترون تک لایه و پرسپترون چند لایه به شرح زیر است:
- معماری: پرسپترون تک لایه فقط یک لایه از نورونها دارد که ورودیها را میگیرد و خروجی تولید میکند. در حالی که پرسپترون چند لایه دارای یک یا چند لایه پنهان از نورونها بین لایههای ورودی و خروجی است.
پیچیدگی: پرسپترون تک لایه یک طبقهبندیکننده خطی ساده است که فقط میتواند الگوهای قابل تفکیک خطی را یاد بگیرد. در حالی که پرسپترون چند لایه میتواند الگوهای پیچیدهتر و غیرخطی را با استفاده از توابع فعالسازی غیرخطی در لایههای پنهان یاد بگیرد. - یادگیری: پرسپترونهای تک لایه از یک قاعده یادگیری ساده پرسپترون برای بهروزرسانی وزنهای خود در طول دوره آموزش استفاده میکنند. در مقابل، پرسپترونهای چند لایه از الگوریتم پیچیدهتری به نام بازگشت به عقب برای آموزش وزنهای خود بهره میبرند که شامل هم پیشروی ورودیها از طریق شبکه و هم بازگشت به عقب خطاها برای بهروزرسانی وزنها میشود.
- خروجی: پرسپترونهای تک لایه یک خروجی دودویی تولید میکنند که نشان میدهد ورودی به کدام یک از دو کلاس ممکن تعلق دارد. در حالی که پرسپترونهای چند لایه میتوانند خروجیهای با مقدار واقعی تولید کنند که این امکان را به آنها میدهد تا علاوه بر طبقهبندی، کارهای رگرسیونی را نیز انجام دهند.
- کاربردها: پرسپترونهای تک لایه برای وظایف طبقهبندی خطی ساده مناسب هستند، در حالی که پرسپترونهای چند لایه برای وظایف طبقهبندی پیچیدهتر که در آن دادههای ورودی به صورت خطی جدا نمیشوند، و همچنین برای وظایف رگرسیون که در آن خروجیها متغیرهای پیوسته هستند، مناسبتر هستند.
۱۰. شبکههای عصبی پیشرونده چه هستند؟
یک شبکه عصبی پیشرونده (FNN) نوعی شبکه عصبی مصنوعی است که در آن نورونها به صورت لایهها چیده شدهاند و اطلاعات فقط در یک جهت جریان دارند، از لایه ورودی به لایه خروجی، بدون هیچ اتصال بازخوردی. اصطلاح "پیشرونده" به این معنا است که اطلاعات به جلو از طریق شبکه عصبی در یک جهت واحد از لایه ورودی از طریق یک یا چند لایه پنهان به لایه خروجی بدون هیچ حلقه یا سیکلی جریان دارند.
یادگیری: در شبکههای عصبی پیشرونده (FNN)، وزنها پس از مرحله پیشروی بهروزرسانی میشوند. در این مرحله، ورودیها تغذیه شده و پس از یک سری تبدیلات غیرخطی، پیشبینیها محاسبه میشوند. سپس این پیشبینیها با خروجی واقعی مقایسه شده و خطاها محاسبه میگردند.
در مرحله بازگشت به عقب یا همان پس انتشار، بر اساس تفاوتها، خطا ابتدا به لایه خروجی منتقل شده و گرادیان تابع زیان نسبت به خروجی محاسبه میشود. این گرادیان سپس به عقب در شبکه منتقل شده و گرادیان تابع زیان نسبت به وزنها و بایاسهای هر لایه محاسبه میشود. در اینجا، قوانین زنجیرهای حساب دیفرانسیل و انتگرال با توجه به وزن و بایاس برای یافتن گرادیان به کار گرفته میشوند. این گرادیانها سپس برای بهروزرسانی وزنها و بایاسهای شبکه استفاده میشوند تا عملکرد آن در وظیفه مورد نظر بهبود یابد.
۱۱. GPU چیست؟
واحد پردازش گرافیکی، که گاهی اوقات به عنوان GPU شناخته میشود، یک مدار الکترونیکی تخصصی است که برای رندر کردن گرافیکها و تصاویر در یک کامپیوتر یا دستگاه دیجیتالی به طور سریع و مؤثر طراحی شده است.
اصلاً برای استفاده در بازیهای ویدئویی و برنامههای گرافیکی دیگر توسعه یافته، GPUها در تعدادی از حوزهها، مانند هوش مصنوعی، یادگیری ماشین، و تحقیقات علمی، که در آنها برای تسریع وظایف محاسباتی سنگین مانند آموزش شبکههای عصبی عمیق استفاده میشوند، اهمیت پیدا کردهاند.
یکی از مزایای اصلی GPUها توانایی آنها در انجام محاسبات موازی است که با استفاده از تعداد زیادی هسته پردازشی، محاسبات پیچیده را سرعت میبخشد. چون دستکاری دادههای با بعد بالا و عملیاتهای ماتریسی به طور مکرر در یادگیری ماشین و سایر برنامههای مبتنی بر داده استفاده میشوند، این فعالیتها به ویژه برای GPUها مناسب هستند.
۱۲. لایههای مختلف در شبکههای عصبی مصنوعی (ANN) چیستند؟
معمولاً سه نوع لایه مختلف در یک شبکه عصبی مصنوعی (ANN) وجود دارد:
- لایه ورودی: این لایه دادههای ورودی را دریافت کرده و به لایه بعدی منتقل میکند. لایه ورودی معمولاً به عنوان یکی از لایههای پنهان شبکه به حساب نمیآید.
- لایههای پنهان: لایههایی هستند که بین لایه ورودی و خروجی قرار دارند و وظیفه پردازش دادههای ورودی را بر عهده دارند.
- لایه خروجی: این لایه است که خروجی شبکه را تولید میکند. ممکن است یک مسئله طبقهبندی دودویی فقط یک نورون خروجی داشته باشد، اما یک مسئله طبقهبندی چندکلاسی ممکن است چندین نورون خروجی داشته باشد، یکی برای هر کلاس. تعداد نورونها در لایه خروجی بستگی به نوع مسئلهای که حل میشود دارد.
۱۳. پیشروی و بازگشت به عقب چیست؟
در یادگیری عمیق و شبکههای عصبی، در مرحله پیشروی، دادههای ورودی از لایه ورودی به لایههای پنهان و سپس به لایه خروجی منتقل میشوند. در این فرآیند، هر لایه از شبکه عصبی عملیاتهای ریاضی را روی دادههای ورودی انجام داده و آنها را به لایه بعدی منتقل میکند تا در نهایت خروجی تولید شود.
پس از اتمام پیشروی، مرحله بازگشت به عقب آغاز میشود، که به آن بازگشت به عقب یا بازگشت پشتی نیز گفته میشود. در این مرحله، خروجی تولید شده با خروجی واقعی مقایسه شده و بر اساس تفاوتهای بین آنها، خطا اندازهگیری شده و به عقب در شبکه عصبی منتقل میشود. در اینجا گرادیان تابع زیان نسبت به خروجی محاسبه میشود. سپس این گرادیان به عقب در شبکه منتقل شده و گرادیان تابع زیان نسبت به وزنها و بایاسهای هر لایه محاسبه میشود. در این مرحله، قوانین زنجیرهای حساب دیفرانسیل و انتگرال برای یافتن گرادیان نسبت به وزن و بایاس به کار گرفته میشوند. این گرادیانها سپس برای بهروزرسانی وزنها و بایاسهای شبکه به کار برده میشوند تا عملکرد شبکه در وظیفه مورد نظر بهبود یابد.
به طور خلاصه، مرحله پیشروی شامل ورود دادهها به شبکه عصبی و تولید خروجی است، در حالی که مرحله بازگشت به عقب به استفاده از خروجی برای محاسبه خطا و تنظیم مجدد وزنها و بایاسهای شبکه اشاره دارد.
۱۴. تابع هزینه در یادگیری عمیق چیست؟
تابع هزینه یک تابع ریاضی است که برای سنجش کیفیت پیشبینیها در طول آموزش شبکههای عصبی عمیق به کار میرود. این تابع تفاوتها بین خروجیهای تولید شده در مرحله پیشروی شبکه عصبی و خروجیهای واقعی را، که به عنوان زیانها یا خطاها شناخته میشوند، اندازهگیری میکند. در طول فرآیند آموزش، وزنهای شبکه تنظیم میشوند تا زیانها را کاهش دهند، که این کار با محاسبه گرادیان تابع هزینه نسبت به وزنها و بایاسها با استفاده از الگوریتمهای بازگشت به عقب انجام میشود.
تابع هزینه همچنین به عنوان تابع زیان یا تابع هدف شناخته میشود. در یادگیری عمیق، بسته به نوع مسئله و شبکه عصبی مورد استفاده، انواع مختلفی از توابع هزینه به کار برده میشوند. برخی از توابع هزینه رایج عبارتند از:
- انتروپی متقاطع دودویی برای طبقهبندی دودویی که تفاوت بین احتمال پیشبینی شده نتیجه مثبت و نتیجه واقعی را اندازهگیری میکند.
- انتروپی متقاطع چندکلاسی برای طبقهبندی چندکلاسی که تفاوت بین احتمال پیشبینی شده و توزیع احتمال واقعی را اندازهگیری میکند.
- انتروپی متقاطع چندکلاسی فشرده برای طبقهبندی چندکلاسی که زمانی استفاده میشود که برچسب واقعی به صورت یک عدد صحیح است تا بردار کدگذاری شده یک به یک.
- اختلاف کولبک-لایبلر (KL Divergence) در روشهای یادگیری تولیدی مانند شبکههای عصبی مقابلهای (GANs) و خودرمزنگارهای تغییری (VAEs) به کار میرود و برای اندازهگیری تفاوتها بین دو توزیع احتمالی استفاده میشود.
- میانگین خطای مربعات در رگرسیون برای اندازهگیری میانگین تفاوتهای مربعی بین خروجیهای واقعی و پیشبینیها به کار میرود.
۱۵. توابع فعالسازی در یادگیری عمیق چه هستند و کجا استفاده میشوند؟
یادگیری عمیق از توابع فعالسازی استفاده میکند که عملیاتهای ریاضی هستند که روی خروجی هر نورون در شبکه عصبی انجام میشود تا به شبکه خاصیت غیرخطی ببخشد. هدف از توابع فعالسازی این است که غیرخطی بودن را به شبکه اضافه کند تا بتواند روابط پیچیدهتری بین متغیرهای ورودی و خروجی را یاد بگیرد.
به بیان دیگر، تابع فعالسازی در شبکههای عصبی خروجی عملیات خطی قبلی (که معمولاً جمع وزندار مقادیر ورودی یعنی wx+b است) را به یک محدوده مطلوب نگاشت میکند، زیرا استفاده مکرر از جمع وزندار (یعنی wx +b) منجر به تابعی چندجملهای میشود. تابع فعالسازی خروجی خطی را به خروجی غیرخطی تبدیل میکند که این امر شبکه عصبی را قادر میسازد تا وظایف پیچیدهتری را تقریب بزند.
در یادگیری عمیق، برای محاسبه گرادیانهای تابع زیان نسبت به وزنهای شبکه در طول بازگشت به عقب، توابع فعالسازی باید قابل تفکیک باشند. این امر به شبکه اجازه میدهد تا از روشهای کاهش گرادیان یا سایر تکنیکهای بهینهسازی برای یافتن وزنهای بهینه جهت کاهش تابع زیان استفاده کند.
اگرچه توابع فعالسازی مانند ReLU و Hardtanh دارای ناپیوستگیهای نقطهای هستند، اما در اکثر نقاط قابل تفکیک هستند. گرادیان در نقطه ناپیوستگی تعریف نشده است، اما این مسئله تأثیر چشمگیری بر کل گرادیان شبکه ندارد زیرا گرادیان در این نقاط معمولاً به صفر یا مقدار کوچکی تنظیم میشود.
۱۶. انواع مختلف توابع فعالسازی که در یادگیری عمیق استفاده میشوند چه هستند؟
در یادگیری عمیق، انواع مختلفی از توابع فعالسازی به کار برده میشوند که هر کدام نقاط قوت و ضعف خاص خود را دارند. برخی از توابع فعالسازی رایج عبارتند از:
- تابع سیگموئید: این تابع هر مقداری را بین ۰ و ۱ نگاشت میکند و عمدتاً در مسائل طبقهبندی دودویی به کار میرود، جایی که خروجی لایه پنهان قبلی را به مقدار احتمالی نگاشت میکند.
- تابع سافتمکس: این تابع گسترشیافته سیگموئید برای مسائل طبقهبندی چندکلاسی است که در لایه خروجی شبکه عصبی به کار میرود و خروجی لایه قبلی را به توزیع احتمالی بین کلاسها نگاشت میکند، به طوری که به هر کلاس یک مقدار احتمال بین ۰ و ۱ میدهد و جمع احتمالات بر روی تمام کلاسها برابر با ۱ است. کلاسی که بالاترین مقدار احتمال را دارد به عنوان کلاس پیشبینی شده در نظر گرفته میشود.
- تابع ReLU (واحد خطی اصلاح شده): این تابع غیرخطی مقدار ورودی را برای ورودیهای مثبت برمیگرداند و برای ورودیهای منفی ۰ را برمیگرداند. این تابع به دلیل سادگی و کارایی بالا به طور گسترده در شبکههای عصبی عمیق به کار میرود.
- تابع Leaky ReLU: این تابع شبیه به ReLU است، اما برای جلوگیری از نورونهای غیرفعال، برای مقادیر ورودی منفی یک شیب کوچک اضافه میکند.
- تابع Tanh (تانژانت هایپربولیک): این تابع فعالسازی غیرخطی مقادیر ورودی را بین -۱ تا ۱ نگاشت میکند. این تابع شبیه به سیگموئید است اما نتایج مثبت و منفی را فراهم میکند و عمدتاً در وظایف رگرسیون که خروجیها مقادیر پیوسته هستند، به کار میرود.
۱۷. شبکههای عصبی چگونه از دادهها یاد میگیرند؟
در شبکههای عصبی، روشی به نام بازگشت به عقب در طول آموزش شبکه برای تنظیم وزنها و بایاسها به کار میرود. این روش گرادیان تابع هزینه را نسبت به پارامترهای شبکه محاسبه میکند و سپس پارامترهای شبکه را با استفاده از الگوریتمهای بهینهسازی در جهت مخالف گرادیان بهروزرسانی میکند تا زیانها را کاهش دهد.
در طول آموزش، در مرحله پیشروی، دادههای ورودی از طریق شبکه عبور کرده و خروجی تولید میکنند. سپس تابع هزینه این خروجی تولیدی را با خروجی واقعی مقایسه میکند. پس از آن، بازگشت به عقب گرادیان تابع هزینه را نسبت به خروجی شبکه محاسبه میکند. این گرادیان سپس به عقب در شبکه منتقل شده و گرادیان تابع زیان نسبت به وزنها و بایاسهای هر لایه محاسبه میشود. در اینجا، قوانین زنجیرهای مشتقگیری نسبت به پارامترهای هر لایه برای یافتن گرادیان به کار گرفته میشوند.
پس از محاسبه گرادیان، از الگوریتمهای بهینهسازی برای بهروزرسانی پارامترهای شبکه استفاده میشود. برخی از الگوریتمهای بهینهسازی متداول عبارتند از کاهش گرادیان تصادفی (SGD) و دستهای کوچک و غیره.
هدف از فرآیند آموزش، کاهش تابع هزینه با تنظیم وزنها و بایاسها در طول بازگشت به عقب است.
۱۸. چگونه تعداد لایههای پنهان و تعداد نورونها در هر لایه پنهان انتخاب میشوند؟
هیچ راه حل یکسانی برای این مسئله وجود ندارد، بنابراین انتخاب تعداد لایههای پنهان و نورونها در هر لایه پنهان در شبکه عصبی اغلب بر اساس مشاهدات عملی و تجربه است. با این حال، چند اصل کلی و قاعده انگشتی وجود دارد که میتوان به عنوان یک پایه استفاده کرد.
- تعداد لایههای پنهان میتواند بر اساس پیچیدگی مسئلهای که در حال حل شدن است تعیین شود. مسائل ساده ممکن است با یک لایه پنهان حل شوند، در حالی که مسائل پیچیدهتر ممکن است به دو یا چند لایه پنهان نیاز داشته باشند. اما افزودن لایههای بیشتر نیز خطر بیشبرازش را افزایش میدهد، بنابراین تعداد لایهها باید بر اساس تعادل بین پیچیدگی مدل و عملکرد تعمیم انتخاب شود.
- تعداد نورونها در هر لایه پنهان میتواند بر اساس تعداد ویژگیهای ورودی و سطح مطلوب پیچیدگی مدل تعیین شود. هیچ قاعده سخت و سریعی وجود ندارد و تعداد نورونها میتواند بر اساس نتایج آزمایش و اعتبارسنجی تنظیم شود.
در عمل، اغلب توصیه میشود که با یک مدل ساده شروع کرده و به تدریج پیچیدگی آن را افزایش دهیم تا به عملکرد دلخواه برسیم. این روند میتواند شامل افزودن تعداد بیشتری لایههای پنهان یا نورونها باشد یا آزمایش با ساختارها و هایپرپارامترهای متفاوت. همچنین مهم است که به طور مرتب عملکرد آموزش و اعتبارسنجی را برای تشخیص بیشبرازش رصد کرده و در صورت نیاز مدل را تنظیم کنیم.
۱۹. بیشبرازش چیست و چگونه میتوان از آن جلوگیری کرد؟
بیشبرازش یک مشکل در یادگیری ماشین است که زمانی اتفاق میافتد که مدل یاد میگیرد دادههای آموزشی را به گونهای دقیق برازش کند که شروع به درگیر شدن با نویز و الگوهای غیرمهم میکند. به این دلیل، مدل در دادههای آموزشی عملکرد خوبی دارد اما در دادههای جدید و آزمایش نشده عملکرد ضعیفی از خود نشان میدهد، که منجر به عملکرد تعمیم پایین میشود.
برای جلوگیری از بیشبرازش در یادگیری عمیق میتوانیم از تکنیکهای زیر استفاده کنیم:
- سادهسازی مدل: احتمال بیشبرازش در یک مدل سادهتر با تعداد کمتری لایهها و پارامترها کمتر است. در کاربردهای عملی، اغلب مفید است که با یک مدل ساده شروع کنیم و به تدریج پیچیدگی آن را افزایش دهیم تا عملکرد مطلوب به دست آید.
- نظم دهی(Regularization): نظم دهی یک تکنیک استفاده شده در یادگیری ماشین برای جلوگیری از بیشبرازش مدل با افزودن یک شرط جریمه است، که محدودیتی بر وزن مدل اعمال میکند. برخی از رایجترین تکنیکهای نظم دهی به شرح زیر است:
- نظم دهی L1 و L2: نظم دهی L1 مدل را با قرار دادن بسیاری از وزنهای مدل برابر با ۰ پراکنده میکند در حالی که نظم دهی L2 وزن اتصال شبکه عصبی را محدود میکند.
- حذف تصادفی: حذف تصادفی یک تکنیک است که به طور تصادفی برخی از نورونهای به طور تصادفی انتخاب شده را حذف یا غیرفعال میکند. این پس از توابع فعالسازی لایه پنهان اعمال میشود. معمولاً به یک مقدار کوچک مانند ۰.۲ یا ۰.۲۵ تنظیم میشود. برای مقدار حذف تصادفی ۰.۲۰، هر نورون در لایه پنهان قبلی ۲۰% شانس غیرفعال بودن دارد. فقط در طول فرآیند آموزش عملیاتی است.
- نظم دهی حداکثر-نرم: این محدودیت بزرگی وزنها در یک شبکه عصبی را با تنظیم یک حداکثر محدودیت (یا نرم) بر وزنهای نورونها، به گونهای که مقادیر آنها نمیتواند از این حد فراتر رود، محدود میکند.
- افزایش دادههای آموزشی: با افزایش حجم دادهها، میتوانیم به مدل مجموعهای متنوع از نمونهها برای یادگیری ارائه دهیم که این کار میتواند در جلوگیری از بیشبرازش مفید باشد.
- توقف زودهنگام: این روش شامل نظارت بر عملکرد مدل روی مجموعه اعتبارسنجی در طول آموزش است و زمانی که کاهش زیان اعتبارسنجی متوقف شود، آموزش را پایان میدهد.
۲۰. دوره (epoch)، تکرار (iterations)، و دستهها (batches) را تعریف کنید.
یک دوره کامل آموزش مدل یادگیری عمیق با استفاده از کل دادههای آموزشی، دوره نامیده میشود. در طول یک دوره، هر نمونه آموزشی در مجموعه دادهها توسط مدل پردازش شده و وزنها و بایاسهای آن بر اساس زیان یا خطای برآورد شده تنظیم میشوند. تعداد دورهها میتواند از یک تا بینهایت متغیر باشد و بر اساس ورودی کاربر تعیین میشود و همیشه یک مقدار صحیح است.
تکرار به فرآیند اجرای یک دسته داده از طریق مدل، محاسبه زیان و تغییر پارامترهای مدل اشاره دارد. بسته به تعداد دستهها در مجموعه دادهها، یک یا چند تکرار ممکن است در طول یک دوره انجام شود.
یک دسته در یادگیری عمیق، زیرمجموعهای از دادههای آموزشی است که برای تغییر وزنهای مدل در طول آموزش به کار میرود. در آموزش دستهای، کل مجموعه آموزشی به گروههای کوچکتر تقسیم شده و مدل پس از تجزیه و تحلیل هر دسته بهروزرسانی میشود. یک دوره میتواند شامل یک یا چند دسته باشد.
- اندازه دسته همیشه بیشتر از یک و کمتر از تعداد کل نمونهها خواهد بود.
- اندازه دسته یک هایپرپارامتر است که توسط کاربر تنظیم میشود و تعداد تکرارها در هر دوره با تقسیم تعداد کل نمونههای آموزشی بر اندازه هر دسته محاسبه میشود.
مجموعههای داده آموزشی یادگیری عمیق اغلب به دستههای کوچکتر تقسیم شده و مدل هر دسته را به ترتیب و یکی پس از دیگری در طول هر دوره تجزیه و تحلیل میکند. عملکرد مدل میتواند پس از هر دوره روی مجموعه دادههای اعتبارسنجی ارزیابی شود که این کار به نظارت بر پیشرفت مدل کمک میکند.
برای مثال: فرض کنید ما ۵۰۰۰ نمونه آموزشی در مجموعه دادههای آموزشی داریم. علاوه بر این، میخواهیم مجموعه دادهها را به ۱۰۰ دسته تقسیم کنیم. اگر تصمیم بگیریم از پنج دوره استفاده کنیم، تعداد کل تکرارها به شرح زیر خواهد بود:
Total number of training samples = 5000
Batch size = 100
Total number of iterations=Total number of training samples/Batch size=5000/100=50
Total number of iterations = 50
One epoch = 50 iterations
Total number of iterations in 5 epochs = 50*5 = 250 iterations.
۲۱. نرخ یادگیری در یادگیری عمیق را تعریف کنید.
نرخ یادگیری در یادگیری عمیق یک هایپرپارامتر است که کنترل میکند بهینهساز چقدر مکرر وزنهای شبکه عصبی را در حین آموزش تنظیم میکند. این مشخص میکند که اندازه گامی که بهینهساز به طور مکرر پارامترهای مدل را با توجه به تابع زیان بهروزرسانی میکند، چقدر است، به طوری که زیانها در طول آموزش به حداقل برسد.
با نرخ یادگیری بالا، مدل ممکن است به سرعت همگرا شود، اما ممکن است از راهحل ایدهآل فراتر رود یا در اطراف آن بپرد. از سوی دیگر، نرخ یادگیری پایین ممکن است باعث شود مدل به آرامی همگرا شود، اما میتواند راهحلی دقیقتر تولید کند.
انتخاب نرخ یادگیری مناسب برای آموزش موفقیتآمیز شبکههای عصبی عمیق بسیار مهم است.
۲۲. تابع زیان انتروپی متقاطع چیست؟
انتروپی متقاطع یک تابع زیان رایج در یادگیری عمیق برای مسائل طبقهبندی است. تابع زیان انتروپی متقاطع تفاوت بین توزیع احتمال واقعی و توزیع احتمال پیشبینی شده را در کلاسها اندازهگیری میکند.
۲۳. کاهش گرادیان چیست؟
کاهش گرادیان قلب فرآیند یادگیری در یادگیری ماشین و یادگیری عمیق است. این روش برای کمینه کردن تابع هزینه یا زیان با تنظیم تکراری پارامترهای مدل، یعنی وزنها و بایاسهای لایه عصبی، به کار میرود. هدف کاهش این تفاوت است که توسط تابع هزینه به عنوان تفاوت بین خروجی پیشبینی شده مدل و خروجی واقعی نمایش داده میشود.
گرادیان بردار مشتقات جزئی آن نسبت به ورودیهایش است که جهت شیب تندترین صعود (گرادیان مثبت) یا شیب تندترین نزول (گرادیان منفی) تابع را نشان میدهد.
در یادگیری عمیق، گرادیان مشتق جزئی تابع هدف یا تابع هزینه نسبت به پارامترهای مدل، یعنی وزنها یا بایاسها، است و این گرادیان برای بهروزرسانی پارامترهای مدل در جهت گرادیان منفی به کار میرود تا بتواند تابع هزینه را کاهش دهد و عملکرد مدل را بهبود ببخشد. میزان بهروزرسانی توسط نرخ یادگیری تعیین میشود که اندازه گام بهروزرسانی را کنترل میکند.
۲۴. چگونه یک مدل یادگیری عمیق را بهینهسازی میکنید؟
یک مدل یادگیری عمیق میتواند با تغییر پارامترها و هایپرپارامترهای خود برای افزایش عملکرد در یک وظیفه خاص بهینهسازی شود. در اینجا چند روش معمول برای بهینهسازی مدل یادگیری عمیق وجود دارد:
انتخاب معماری مناسب
تنظیم نرخ یادگیری
تنظیم مقررات
افزایش دادههای آموزشی
یادگیری انتقالی
تنظیم هایپرپارامتر
۲۵. کاهش گرادیان دستهای، تصادفی و مینی را تعریف کنید.
چندین نوع مختلف از کاهش گرادیان وجود دارد که در نحوه انتخاب اندازه گام یا نرخ یادگیری و نحوه انجام بهروزرسانیها متفاوت هستند. در اینجا برخی از انواع محبوب آنها آمده است:
- کاهش گرادیان دستهای: در این روش، برای بهروزرسانی مقادیر پارامترهای مدل مانند وزن و بایاس، کل مجموعه دادههای آموزشی برای محاسبه گرادیان و بهروزرسانی پارامترها در هر تکرار استفاده میشود. این روش ممکن است برای دادههای بزرگ کند باشد اما میتواند منجر به مدلی دقیقتر شود. این روش برای منحنیهای خطای محدب یا نسبتاً صاف مؤثر است زیرا با گرفتن گامهای بزرگ در جهت گرادیان منفی تابع هزینه، مستقیماً به سمت راهحل بهینه حرکت میکند. با این حال، برای دادههای بزرگ میتواند کند باشد زیرا در هر تکرار با استفاده از کل دادههای آموزشی گرادیان را محاسبه کرده و پارامترها را بهروزرسانی میکند. این میتواند منجر به زمانهای آموزش طولانیتر و هزینههای محاسباتی بیشتر شود.
- کاهش گرادیان تصادفی (SGD): در SGD، فقط یک نمونه آموزشی برای محاسبه گرادیان و بهروزرسانی پارامترها در هر تکرار استفاده میشود. این روش میتواند سریعتر از کاهش گرادیان دستهای باشد اما ممکن است بهروزرسانیها دارای نویز بیشتری باشند.
- کاهش گرادیان مینیبچ: در این روش، یک دسته کوچک از نمونههای آموزشی برای محاسبه گرادیان و بهروزرسانی پارامترها در هر تکرار استفاده میشود. این میتواند تعادل خوبی بین کاهش گرادیان دستهای و کاهش گرادیان تصادفی باشد، زیرا میتواند سریعتر از کاهش گرادیان دستهای و کم نویزتر از کاهش گرادیان تصادفی باشد.
۲۶.انواع مختلف شبکههای عصبی چیست؟
انواع مختلفی از شبکههای عصبی در یادگیری عمیق به کار گرفته میشوند. برخی از مهمترین معماریهای شبکه عصبی عبارتند از:
شبکههای عصبی پیشخور (FFNNs)
شبکههای عصبی کانولوشن (CNNs)
شبکههای عصبی بازگشتی (RNNs)
شبکههای حافظه بلند مدت کوتاه (LSTMs)
واحدهای بازگشتی دروازهای (GRU)
شبکههای عصبی خودرمزنگار (Autoencoder)
مکانیزم توجه (Attention Mechanism)
شبکههای مقابلهای تولیدی (GANs)
ترانسفورمرها (Transformers)
شبکههای باور عمیق (DBNs)
۲۷. تفاوت بین شبکههای کمعمق و شبکههای عمیق چیست؟
شبکههای عمیق و شبکههای کمعمق دو نوع از شبکههای عصبی مصنوعی هستند که میتوانند از دادهها یاد بگیرند و کارهایی مانند طبقهبندی، رگرسیون، خوشهبندی و تولید را انجام دهند.
- شبکههای کمعمق: یک شبکه کمعمق دارای یک لایه پنهان بین لایههای ورودی و خروجی است، در حالی که یک شبکه عمیق دارای چندین لایه پنهان است. به دلیل داشتن پارامترهای کمتر، آموزش آنها آسانتر و از نظر محاسباتی کم هزینهتر از شبکههای عمیق است. شبکههای کمعمق برای وظایف پایهای یا کمپیچیدگی مناسب هستند که در آنها روابط ورودی-خروجی نسبتاً ساده هستند و نیاز به نمایش ویژگی گستردهای ندارند.
- شبکههای عمیق: شبکههای عمیق، که به عنوان شبکههای عصبی عمیق نیز شناخته میشوند، با وجود بسیاری از لایههای پنهان بین لایههای ورودی و خروجی قابل شناسایی هستند. وجود چندین لایه به شبکههای عمیق امکان میدهد تا نمایشهای سلسله مراتبی دادهها را یاد بگیرند، الگوها و ویژگیهای دقیق را در سطوح مختلف انتزاعی به دست آورند. ظرفیت بالاتری برای استخراج ویژگی دارد و میتواند روابط پیچیدهتر و ظریفتری را در دادهها یاد بگیرد. نتایج پیشرفتهای را در بسیاری از وظایف یادگیری ماشین و هوش مصنوعی ارائه داده است.
۲۸. چارچوب(فریمورک) یادگیری عمیق چیست؟
چارچوب یادگیری عمیق مجموعهای از کتابخانهها و ابزارهای نرمافزاری است که به برنامهنویسان امکانات بهتری برای توسعه و آموزش مدلهای یادگیری عمیق میدهد. علاوه بر انتزاعات سطح پایین برای پیادهسازی توابع و توپولوژیهای خاص، یک رابط سطح بالا برای ایجاد و آموزش شبکههای عصبی عمیق ارائه میدهد. TensorFlow، PyTorch، Keras، Caffe و MXNet چند مورد از چارچوبهای شناخته شده برای یادگیری عمیق هستند.
۲۹. منظور از مشکل کاهش گرادیان ناپدید شونده یا منفجر شونده چیست؟
شبکههای عصبی عمیق هنگامی که گرادیانهای تابع هزینه نسبت به پارامترهای مدل در طول آموزش بیش از حد کوچک (ناپدید شونده) یا بیش از حد بزرگ (منفجر شونده) میشوند، با مشکل کاهش گرادیان ناپدید شونده یا منفجر شونده مواجه میشوند.
در مورد کاهش گرادیان ناپدید شونده، تنظیماتی که در طول فاز بازگشت به عقب بر روی وزنها و بایاسها انجام میشوند به دلیل مقادیر بسیار کوچک دیگر معنیدار نیستند. در نتیجه، مدل ممکن است به خوبی عمل نکند زیرا نمیتواند جنبههای مهم دادهها را درک کند.
در مورد کاهش گرادیان منفجر شونده، مدل از سطوح بهینه خود فراتر رفته و نمیتواند به یک راه حل مناسب همگرا شود زیرا بهروزرسانیهای انجام شده بر روی وزنها و بایاسها بیش از حد بزرگ میشوند.
برخی از تکنیکها مانند مقداردهی اولیه وزنها، روشهای نرمالسازی و انتخاب دقیق توابع فعالسازی میتوانند برای مقابله با این مشکلات به کار روند.
۳۰. کلیپینگ گرادیان چیست؟
کلیپینگ گرادیان تکنیکی است که برای جلوگیری از مشکل گرادیان منفجر شونده در طول آموزش شبکههای عصبی عمیق به کار میرود. این تکنیک شامل تغییر مقیاس گرادیان است وقتی که اندازه آن از یک آستانه خاصی فراتر میرود. ایده این است که گرادیان را کلیپ کنیم، یعنی یک مقدار حداکثری برای اندازه گرادیان تعیین کنیم، تا در طول فرآیند آموزش بیش از حد بزرگ نشود. این تکنیک اطمینان میدهد که گرادیانها بیش از حد بزرگ نشوند و از انحراف مدل جلوگیری کنند. کلیپینگ گرادیان به طور معمول در شبکههای عصبی بازگشتی (RNNs) برای جلوگیری از مشکل گرادیان منفجر شونده استفاده میشود.
منبع: geeksforgeeks