هایپرپارامترها متغیرهای پیکربندی هستند که فرآیند یادگیری یک مدل یادگیری ماشین را کنترل میکنند. آنها متفاوت از پارامترهای مدل هستند که وزنها و بایاسهایی هستند که از دادهها یاد گرفته میشوند. چندین نوع مختلف از هایپرپارامترها وجود دارد:
هایپرپارامترها در شبکههای عصبی
شبکههای عصبی چندین هایپرپارامتر اساسی دارند که نیاز به تنظیم دارند، از جمله:
نرخ یادگیری: این هایپرپارامتر اندازه گامی که بهینهساز در هر تکرار آموزش برمیدارد را کنترل میکند. نرخ یادگیری خیلی کوچک میتواند منجر به همگرایی کند شود، در حالی که نرخ یادگیری خیلی بزرگ میتواند منجر به ناپایداری و واگرایی شود.
تعداد دورهها (Epochs): این هایپرپارامتر تعداد دفعاتی که کل مجموعه دادههای آموزشی در طول آموزش از طریق مدل عبور میکند را نشان میدهد. افزایش تعداد دورهها میتواند عملکرد مدل را بهبود بخشد اما اگر به دقت انجام نشود ممکن است منجر به بیشبرازش شود.
تعداد لایهها: این هایپرپارامتر عمق مدل را تعیین میکند که میتواند تأثیر قابل توجهی بر پیچیدگی و توانایی یادگیری آن داشته باشد.
تعداد گرهها در هر لایه: این هایپرپارامتر عرض مدل را تعیین میکند که بر توانایی آن برای نمایش روابط پیچیده در دادهها تأثیر میگذارد.
معماری: این هایپرپارامتر ساختار کلی شبکه عصبی را تعیین میکند، شامل تعداد لایهها، تعداد نورونها در هر لایه و اتصالات بین لایهها. معماری بهینه بستگی به پیچیدگی کار و اندازه مجموعه دادهها دارد.
تابع فعالساز: این هایپرپارامتر غیرخطی بودن را به مدل وارد میکند، که به آن اجازه میدهد تا مرزهای تصمیمگیری پیچیده را یاد بگیرد. توابع فعالسازی رایج شامل سیگموید، تانژانت هایپربولیک (tanh) و واحد خطی اصلاح شده (ReLU) هستند.
هایپرپارامترها در ماشین بردار پشتیبان
برای تنظیم دقیق SVMها، برخی از هایپرپارامترهای اساسی را در نظر میگیریم:
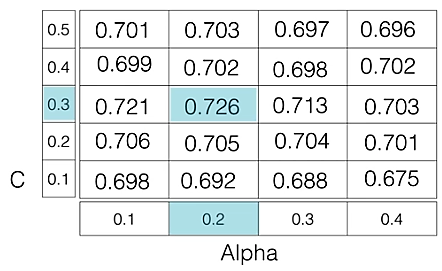
- C: پارامتر تنظیمکننده که تعادل بین حاشیه و تعداد خطاهای آموزشی را کنترل میکند. مقدار بزرگتر C خطاهای آموزشی را سنگینتر جریمه میکند، که منجر به حاشیه کوچکتر اما احتمالاً عملکرد تعمیمپذیری بهتر میشود. مقدار کوچکتر C اجازه میدهد تا خطاهای آموزشی بیشتری وجود داشته باشد اما ممکن است منجر به بیشبرازش شود.
- کرنل: تابع کرنل که شباهت بین نقاط داده را تعریف میکند. کرنلهای مختلف میتوانند روابط مختلف بین نقاط داده را به دست آورند و انتخاب کرنل میتواند تأثیر قابل توجهی بر عملکرد SVM داشته باشد. کرنلهای رایج شامل خطی، چندجملهای، تابع پایه شعاعی (RBF) و سیگموید هستند.
- گاما: این پارامتر تأثیر بردارهای پشتیبان بر مرز تصمیمگیری را کنترل میکند. مقدار بزرگتر گاما نشاندهنده تأثیر قویتر بردارهای پشتیبان نزدیک است، در حالی که مقدار کوچکتر نشاندهنده تأثیر ضعیفتر بردارهای پشتیبان دور است. انتخاب گاما برای کرنلهای RBF بسیار مهم است.
هایپرپارامترها در XGBoost
هایپرپارامترهای ضروری زیر در XGBoost نیاز به تنظیم دارند:
- learning_rate: این هایپرپارامتر اندازه گامی که بهینهساز در هر تکرار آموزش برمیدارد را تعیین میکند. نرخ یادگیری بزرگتر میتواند منجر به همگرایی سریعتر شود، اما همچنین ممکن است خطر بیشبرازش را افزایش دهد. نرخ یادگیری کوچکتر ممکن است منجر به همگرایی کندتر شود اما میتواند به جلوگیری از بیشبرازش کمک کند.
- n_estimators: این هایپرپارامتر تعداد درختان تقویتی که باید آموزش داده شوند را تعیین میکند. تعداد بیشتری از درختان میتواند دقت مدل را بهبود بخشد، اما همچنین ممکن است خطر بیشبرازش را افزایش دهد. تعداد کمتری از درختان ممکن است منجر به دقت پایینتر شود اما میتواند به جلوگیری از بیشبرازش کمک کند.
- max_depth: این هایپرپارامتر حداکثر عمق هر درخت در مجموعه را تعیین میکند. max_depth بزرگتر میتواند به درختان اجازه دهد تا روابط پیچیدهتری را در دادهها به دست آورند، اما همچنین ممکن است خطر بیشبرازش را افزایش دهد. max_depth کوچکتر ممکن است منجر به پیچیدگی کم درختان شود اما میتواند به جلوگیری از بیشبرازش کمک کند.
- min_child_weight: این هایپرپارامتر حداقل مجموع وزن نمونه (هسین) مورد نیاز در یک گره فرزند را تعیین میکند. min_child_weight بزرگتر میتواند به جلوگیری از بیشبرازش کمک کند با اینکه نیاز به دادههای بیشتری برای تأثیرگذاری بر تقسیم درختان دارد. min_child_weight کوچکتر ممکن است به تقسیم تهاجمیتر درختان منجر شود اما همچنین ممکن است خطر بیشبرازش را افزایش دهد.
- subsample: این هایپرپارامتر درصد ردیفهای استفاده شده برای هر ساخت درخت را تعیین میکند. subsample کوچکتر میتواند کارایی آموزش را بهبود بخشد اما ممکن است دقت مدل را کاهش دهد. subsample بزرگتر میتواند دقت را افزایش دهد اما ممکن است هزینه های محاسباتی آموزش را بالا ببرد.
برخی دیگر از مثالهای هایپرپارامترهای مدل عبارتند از:
جریمه در طبقهبندیکننده رگرسیون لجستیک، یعنی نظم دهی L1 یا L2
تعداد درختان و عمق درختان برای جنگلهای تصادفی
نرخ یادگیری برای آموزش یک شبکه عصبی
تعداد خوشهها برای الگوریتمهای خوشهبندی
k در k-نزدیکترین همسایهها
 متلب فا | دنیای تحقیق و پروژه
متلب فا | دنیای تحقیق و پروژه